Excel의 회귀 분석 : 수식, 예. 선형 회귀
회귀 분석은 통계적 방법입니다.하나 이상의 독립 변수에 대한 매개 변수의 의존성을 보여주는 연구. 사전 컴퓨터 시대에, 그것의 사용은 다소 어려웠습니다. 특히 많은 양의 데이터에 관한 문제 였을 때 그렇습니다. 오늘날 Excel에서 회귀 분석을 작성하는 방법을 학습 한 후 복잡한 통계 문제를 단 몇 분 만에 해결할 수 있습니다. 아래는 경제 분야의 구체적인 예입니다.
회귀 유형
바로 그 개념은 1886 년 Francis Galton에 의해 수학에 도입되었습니다. 회귀가 발생합니다.
- 선형;
- 파라볼 릭;
- 힘의 법칙;
- 지수 함수;
- 쌍곡선;
- 표시;
- 로그.
예제 1
6 개 산업 기업의 평균 급여에 대한 집단 퇴직자 수의 의존성을 결정하는 문제를 고려해 보겠습니다.
그 일. 6 개 기업은 평균 월급과 자신의 의지를 포기한 직원 수를 분석했다. 표 형식으로 우리는 :
A | B | C | |
1 | X | 사임 한 사람 수 | 급여 |
2 | y | 30000 루블 | |
3 | 1 | 60 | 35,000 루블 |
4 | 2 | 35 | 40000 루블 |
5 | 3 | 20 | 45,000 루블 |
6 | 4 | 20 | 5 만 루블 |
7 | 5 | 15 | 55,000 루블 |
8 | 6 | 15 | 60000 루블 |
6 개 기업에서 평균 급여를 떠난 직원 수의 의존성을 결정하는 문제에 대해 회귀 모델은 방정식 Y = a0 + a1x1 + ... + akxk, 여기서 x나는 - 영향을주는 변수, a나는 - 회귀 계수 및 k - 계수의 수
이 작업에서 Y는 퇴사 한 직원의 지표이며 영향을주는 요인은 X로 표시된 급여입니다.
Excel 테이블 프로세서 사용
Excel의 회귀 분석이 선행되어야합니다.사용 가능한 데이터에 내장 함수를 적용합니다. 그러나 이러한 목적을 위해 매우 유용한 애드온 "분석 패키지"를 사용하는 것이 좋습니다. 활성화하려면 다음이 필요합니다.
- "파일"탭에서 "매개 변수"섹션으로 이동하십시오.
- 열려있는 창에서 "추가 기능"행을 선택하십시오.
- "관리"라인의 오른쪽 하단에있는 "이동"버튼을 클릭하십시오;
- "Analysis Package"이름 옆에 체크 표시를하고 "OK"를 클릭하여 작업을 확인하십시오.
모든 것이 올바르게 완료되면 Excel 워크 시트 위에있는 데이터 탭의 오른쪽에 필요한 단추가 나타납니다.
Excel 선형 회귀 분석
이제 우리는 계량 경제 학적 계산을 수행하는 데 필요한 모든 가상 도구를 손에 넣었으므로 문제의 해결 방법을 진행할 수 있습니다. 이것을 위해 :
- "데이터 분석"버튼을 클릭하십시오;
- 창이 열리면 "회귀 분석"버튼을 클릭하십시오.
- 나타나는 탭에서 Y (출퇴근 인원 수)와 X (급여)의 값 범위를 입력하십시오.
- "확인"버튼을 눌러 동작을 확인하십시오.
결과적으로 프로그램이 자동으로 채워집니다.새로운 시트 표 프로세서 회귀 분석 데이터. 주의! Excel에는 이러한 용도로 선호하는 장소를 독립적으로 정의 할 수있는 기능이 있습니다. 예를 들어, Y와 X의 값이있는 시트와 동일한 시트이거나 심지어 그러한 데이터를 저장하기 위해 특별히 고안된 새로운 책일 수 있습니다.
R-square에 대한 회귀 분석 결과
Excel에서 고려한 예제의 데이터를 처리하는 동안 얻은 데이터는 다음과 같습니다.

우선,주의를 기울여야합니다.R- 제곱 값. 그것은 결정의 계수입니다. 이 예에서, R- 제곱 = 0.755 (75.5 %), 즉 모델의 계산 된 파라미터는 고려 된 파라미터 간의 의존을 75.5 % 설명한다. 결정 계수의 값이 높을수록 선택된 모델은 특정 작업에 더 적합한 것으로 간주됩니다. R- 제곱 값이 0.8보다 클 때 실제 상황을 정확하게 설명한다고 믿어진다. R-square가 0.5보다 작 으면 Excel에서 이러한 회귀 분석을 합리적인 것으로 간주 할 수 없습니다.
비율 분석
숫자 64.1428은 Y의 값이 무엇인지 나타냅니다.우리가 고려중인 모델의 모든 변수 xi가 재설정되면. 즉, 분석 된 매개 변수의 값이 특정 모델에 설명되지 않은 다른 요인의 영향을받는다고 주장 할 수 있습니다.
다음 계수는 -0.16285이며셀 B18은 Y에 대한 변수 X의 효과의 가중치를 나타냅니다. 이는 고려중인 모델 내의 직원의 월 평균 월급이 -0.16285의 무게로 남은 사람의 수에 영향을 미친다는 것을 의미합니다. 즉 영향력이 아주 적습니다. 기호 "-"는 계수가 음수 값을 가짐을 나타냅니다. 기업의 급여가 높을수록 고용 계약을 해지하거나 은퇴하려는 욕구를 표현하는 사람이 적다는 것을 우리 모두 알고 있기 때문에 이는 명백합니다.
다중 회귀 분석
이러한 용어는 다음과 같은 형식의 여러 독립 변수가있는 관계 방정식으로 이해됩니다.
y = f (x1+ x2+ ... Xm) + ε이고, 여기서 y는 유효 피쳐 (종속 변수)이고 x1, x2... xm - 이들은 징후 요인 (독립 변수)입니다.
매개 변수 평가
다중 회귀 (MR)의 경우 최소 제곱 법 (OLS)을 사용하여 수행됩니다. Y = a + b 형태의 선형 방정식1x1 + ... + bmxm+ ε는 정상 방정식의 체계를 구축한다 (아래 참조)
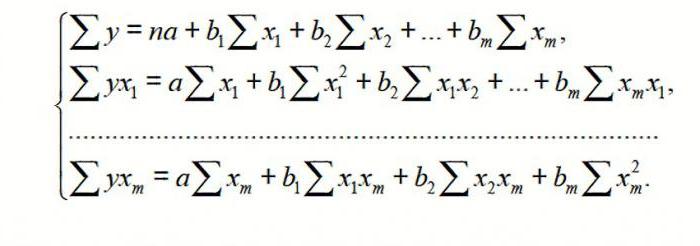
이 방법의 원리를 이해하려면 두 가지 경우를 고려하십시오. 그런 다음 수식으로 설명 된 상황이 발생합니다.

여기에서 우리는 얻는다 :

여기서 σ는 인덱스에 반영되는 해당 특성의 분산입니다.
OLS는 표준화 된 척도의 MR 방정식에 적용 할 수 있습니다. 이 경우 다음 방정식을 얻습니다.

여기서 ty, tx1, ...~xm - 평균값이 0 인 표준화 된 변수; β나는 - 표준화 된 회귀 계수 및 표준 편차 - 1.
모든 β나는 이 경우 정규화 된 것으로 주어진다.중앙 집중 형이므로 서로 비교하면 정확하고 타당한 것으로 간주됩니다. 또한 βi 값이 가장 낮은 요인을 제외하고 요인을 차단하는 것이 일반적입니다.
선형 회귀 식을 사용한 문제
지난 8 개월 동안 특정 상품 N에 대한 가격 동력학 표가 있다고 가정합니다. 1,850 루블 / 톤의 가격으로 파티 인수의 편의성을 결정해야합니다.
A | B | C | |
1 | 월 번호 | 이달의 이름 | 상품의 가격 N |
2 | 1 | 1 월 | 톤당 1750 루블 |
3 | 2 | 2 월 | 톤당 1755 루블 |
4 | 3 | 3 월 | 톤당 1767 루블 |
5 | 4 | 4 월 | 톤당 1760 루블 |
6 | 5 | 5 월 | 톤당 1770 루블 |
7 | 6 | 6 월 | 톤당 1790 루블 |
8 | 7 | 7 월 | 톤당 1810 루블 |
9 | 8 | 8 월 | 톤당 1840 루블 |
표 형식의 프로세서에서이 문제를 해결하려면위의 예제에서 이미 알려진 데이터 분석 도구를 사용하려면 Excel이 필요합니다. 그런 다음 "회귀 분석"섹션을 선택하고 매개 변수를 설정하십시오. "입력 간격 Y"필드에서 종속 변수 (이 경우 특정 달의 특정 달의 가격) 및 독립 입력란의 "입력 간격 X"값의 범위를 입력해야한다는 것을 기억해야합니다. "확인"을 눌러 동작을 확인하십시오. 새 시트 (표시된 경우)에서 회귀 데이터를 얻습니다.
우리는 y = ax + b 형태의 선형 방정식을 만듭니다.매개 변수 a 및 b는 회귀 분석 결과와 함께 달 번호와 계수 및 시트에서 선 "Y 교차"의 이름이있는 행의 계수입니다. 따라서 문제 3에 대한 선형 회귀 방정식 (SD)은 다음과 같은 형식으로 작성됩니다.
제품의 가격은 N = 11.714 * 월 번호 + 1727.54입니다.
또는 대수 표기법
y = 11.714 x + 1727.54
결과 분석
결과 방정식이 적절한 지 결정하기선형 회귀 분석에서 피셔 (Fisher) 기준과 학생 기준뿐만 아니라 다중 상관 계수 (KMK)와 결정 계수가 사용됩니다. Excel 표에서 회귀 결과는 각각 R, R- 제곱, F- 통계 및 T- 통계의 이름 아래에 표시됩니다.
KMK R은 친밀감을 평가할 기회를 제공합니다.독립 변수와 종속 변수 사이의 확률 론적 관계. 이 값이 높으면 "달 수"와 "톤당 루블 가격 N"의 변수 사이에 상당히 강한 관계가 있음을 나타냅니다. 그러나이 연결의 본질은 아직 알려지지 않았습니다.
결정 계수 R의 제곱2(RI)는 수치 적 특성전체 산란의 비율 및 실험 데이터의 산란 부분, 즉 종속 변수의 값은 선형 회귀 방정식에 해당합니다. 고려중인 문제에서이 값은 84.8 %와 동일합니다. 즉, 통계 데이터는 얻어진 SD에 의해 높은 정확도로 기술됩니다.
피셔의 기준이라고도 불리는 F- 통계는 선형 관계의 중요성을 평가하고 그 존재에 대한 가설을 확인하거나 확인하는 데 사용됩니다.
t- 통계 (학생의 기준)의 가치는 미지 또는 자유 용어 선형 의존성이있는 계수의 중요성을 평가하는 데 도움이됩니다. t-test> t의 값cr, 선형 방정식의 자유 항이 중요하지 않음에 대한 가설은 기각된다.
자유 멤버 문제Excel 도구를 사용하여 t = 169,20903, p = 2,89ß-12로 구해졌습니다. 즉, 자유 용어의 중요하지 않은 가설이 거절 될 확률은 0입니다. 알 수없는 계수는 t = 5.79405, p = 0.001158. 다시 말해, 미지의 계수의 중요도에 대한 올바른 가설을 기각 할 확률은 0.12 %입니다.
따라서, 결과적인 선형 회귀 방정식이 적절하다고 주장 될 수있다.
스테이크를 사는 것이 바람직하다는 문제
Excel의 다중 회귀는 동일한 데이터 분석 도구를 사용하여 수행됩니다. 특정 응용 프로그램을 고려하십시오.
NNN 경영진은 결정을 내려야합니다.JSC MMM 지분의 20 %를 매입하는 편의에 패키지 비용 (JV)은 7 천만 달러입니다. NNN 전문가는 유사한 거래에 대한 데이터를 수집했습니다. 다음과 같은 매개 변수에 의해 지분 가치를 추정하기로 결정되었으며, 수백만 달러의 미국 달러로 표시됩니다.
- 미지급금 (VK);
- 연간 매출액 (VO);
- 미수금 (VD);
- 고정 자산 (SOF)의 가치.
또한 매개 변수는 수천 달러의 기업 급여 체납 (V3P)으로 사용됩니다.
Excel 스프레드 시트 프로세서를 통한 솔루션
우선 소스 데이터 테이블을 작성해야합니다. 그것은 다음과 같은 형식을 가지고 있습니다 :

다음 :
- "데이터 분석"창을 호출하십시오.
- "회귀 분석"섹션을 선택하십시오.
- "입력 간격 Y"창에서 열 G의 종속 변수 값 범위를 입력하십시오.
- "입력 간격 X"창의 오른쪽에있는 빨간색 화살표가있는 아이콘을 클릭하고 B, C, D, F 열의 모든 값 범위를 시트에서 선택하십시오.
"새 워크 시트"항목을 선택하고 "확인"을 클릭하십시오.
이 작업에 대한 회귀 분석을하십시오.

결과 및 결론의 검토
Excel 스프레드 시트 프로세서 시트에 위에 제시된 반올림 데이터에서 회귀 방정식을 "수집합니다."
SP = 0.103 * SOF + 0.541 * VO - 0.031 * VK + 0.405 * VD + 0.691 * VZP - 265.844.
좀 더 익숙한 수학적 형식으로 다음과 같이 쓸 수 있습니다.
y = 0.103 * x1 + 0.541 * x2 - 0.031 * x3 + 0.405 * x4 + 0.691 * x5 - 265.844
MMM에 대한 데이터는 표에 나와 있습니다.
SOF, USD | VO, USD | VK, USD | VD, USD | VZP, USD | SP, USD |
102,5 | 535,5 | 45,2 | 41,5 | 21,55 | 64,72 |
그것들을 회귀 방정식에 대입하면숫자는 6 천 4 백 7 십만 달러입니다. 이것은 JSC MMM의 주식이 획득되어서는 안된다는 것을 의미합니다. 그 가치가 7 천만 달러로 상당히 높기 때문입니다.
보시다시피, Excel 테이블 프로세서와 회귀 방정식을 사용하면 매우 구체적인 거래의 실현 가능성에 대한 정보에 근거한 결정을 내릴 수있었습니다.
이제 회귀가 무엇인지 알 수 있습니다. 위에 설명 된 Excel의 예는 계량 경제학 분야의 실질적인 문제를 해결하는 데 도움이됩니다.